Blog
Use custom data in ChatGPT with JavaScript and Postgres
Learn how to feed ChatGPT with custom data stored in Postgres in a JavaScript application.
I recently ran into a case where I wanted to use my own data with ChatGPT. This led me down a rabbit hole of training models, fine tuning, Retrieval Augmented Generation (RAG) and vector databases. While I have worked on a lot of different software projects over the years, there were an unusual amount of unknowns for me in this case.
One thing I had tried before to get custom data into ChatGPT was to simply pass it into the prompt. This worked fine as long as the data fit into the context window.
This time however, I wanted to feed ChatGPT with the content of some PDF and CSV files I had laying around.
It was time to dig into the buzzwords:
- RAG (Retrieval Augmented Generation) sounded like rocket science to me. After a bit of reading however, it didn't feel like that any more. RAG is about fetching a small subset of the data that is relevant to the current prompt and adding it to the prompt context.
- Vector database. A vector is a way to store data that enables querying for similar data. In my case, I wanted to store vector representations of the text data so that I could find the relevant data for the prompt used in ChatGPT.
So, how do we combine these to get custom data into ChatGPT using JavaScript and a Postgres database?
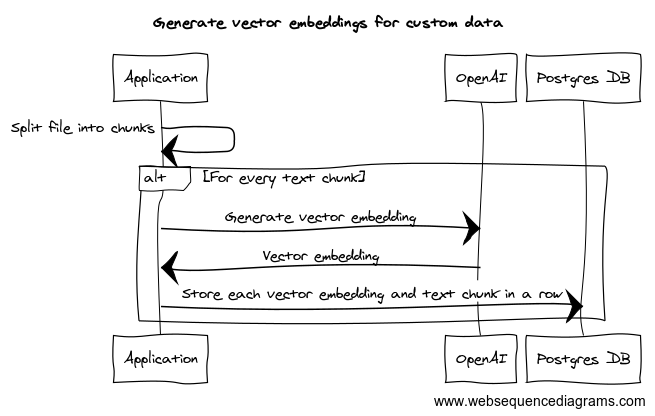
What you will need:
- A Postgres database with pgvector enabled
- A database table where you can store the embeddings. I used this schema:
CREATE TABLE "embeddings" ( "text" varchar, "data" vector, "token_count" int4 ). - An application that can communicate with the Postgres database and OpenAIs APIs
Follow these steps to store your data:
- Break the data that you want to use up into smaller text chunks (I am using a chunk size of 1024 characters)
- For each chunk:
- Generate a vector embedding for each text chunk using the OpenAI Embeddings API
import OpenAI from 'openai'; const openai = new OpenAI({ apiKey: 'your-api-key', }); const embedding = await openai.embeddings.create({ input: 'text-chunk', model: 'text-embedding-ada-002', // Can be any model supported by OpenAI }); const data = embedding.data[0].embedding; - Store the embedding along with the text chunk and token count in your Postgres database
INSERT INTO "embeddings" VALUES ('text-chunk', 'data', 'token-count')
Once all chunks are stored in the database, we can start using it in ChatGPT. Follow these steps to query ChatGPT with your custom data:
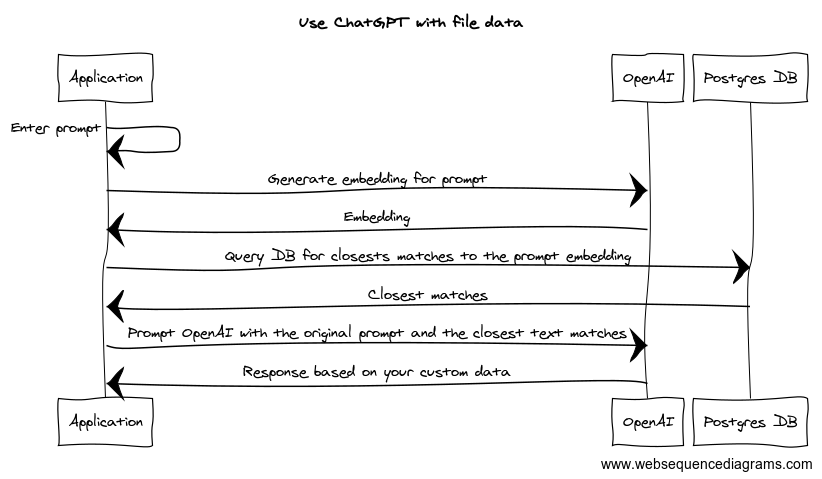
1. Create an embedding for the prompt that you want to use:
const embedding = await openai.embeddings.create({ input: 'my prompt', model: 'text-embedding-ada-002' }); // Can be any model supported by OpenAI
const data = embedding.data[0].embedding;2. Find the text chunks that are most closely related to the prompt in Postgres:
SELECT text FROM "embeddings" ORDER BY data <-> 'data' LIMIT 10;3. Now that you have all the text chunks related to the prompt, you can pass them in as a single string along with the prompt into the ChatGPT API call:
const prompt = 'my prompt';
const chunks = await getChunksFromDb(prompt); // Fetch all relevant chunks from the database
const context = chunks.join(''); // Join all chunks into a single string
const messages = [
{ role: 'system', content: `Context: ${context}` },
{ role: 'user', content: 'prompt' },
];
// Call ChatGPT
const response = await openai.chat.completions.create({
messages,
model: 'gpt-3.5-turbo', // Use any model supported by OpenAI
});
This will inject relevant data into the prompt for use in ChatGPT.
© 2024 Clevis. All Rights reserved